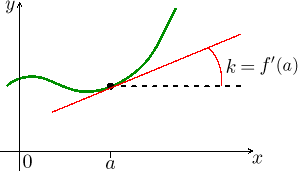
We start by recalling the major interpretations of derivative for a function
of one variable. If we choose a certain value
The third useful point of view tells us that using derivative we can approximate values of the function on some neighborhood of a using the tangent line, the formula is (two versions)
![]()
None of these interpretations works with functions of more variables. It is
enough to look at a picture for the case of two variables: When we choose a
point ![]() ∈D( f )
∈D( f )![]() is obvious: Depends
which way we go, because unlike the case of one variable (left, right), here
we have an amazing freedom of movement.
is obvious: Depends
which way we go, because unlike the case of one variable (left, right), here
we have an amazing freedom of movement.

However, this observation brings us to one classical notion. If somebody
does tell us in which direction to go from
![]() , then the question how fast
the graph grows does make sense.
, then the question how fast
the graph grows does make sense.
Example.
Consider the function
![]() = (1,2).
= (1,2).![]() = (h,k)?
= (h,k)?
We move on the line given by the parametric equation
This is just another example of slicing, as we saw it already in the
first section.
We cut the graph of f with a vertical plane above the line given
by the formula
![]() + t
+ t![]()
Indeed, we have got a function
φ of one variable that we can
differentiate, the value of derivative at time
![]() .
.
![]()
Geometrically speaking, the graph of the function f was sliced by a vertical plane and this slice is now a one-dimensional situation where we easily determine the derivative.
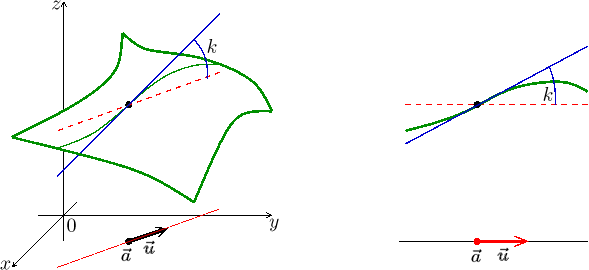
For instance, if we start off from the point
![]() in the direction
in the direction
![]() = (−1,1),
= (−1,1),![]() .
However, this is a
relative quantity, depending on the speed at which we move. Since the
directional vector
.
However, this is a
relative quantity, depending on the speed at which we move. Since the
directional vector
![]() is not of magnitude 1, our subjective slice does
not coincide with the real slice through the graph; therefore also the
result 2 has nothing to do with the change of the graph of f.
is not of magnitude 1, our subjective slice does
not coincide with the real slice through the graph; therefore also the
result 2 has nothing to do with the change of the graph of f.
As we discussed, in order to get compatible results we have to use only directional vectors of size 1. In our case we would use the vector
![]()
Repeating the calculations above we find that in this direction, the graph of f is changing at the rate
![]()
This information now has a geometric meaning as well, for instance it gives
the slope of a "directional tangent line", that is, the tangent line that
we would construct using the real slice through the graph at
![]() .
.
Using the tangent line we are now able to approximate values of the function
in the direction ![]() .
For the function φ we have
.
For the function φ we have
![]() and pass back to f, we get the formula
and pass back to f, we get the formula
![]()
Substition
![]()
leads to an equivalent but more pleasant formula
![]()
In fact, if we are interested in approximation that we need not normalize.
The formula
![]() and we get the nicer
form of approximation above right away.
and we get the nicer
form of approximation above right away.
In any case, the conclusion is that if we want to
move from ![]() only in that particular direction, then we can approximate
values of the function (for small s) using the formula
only in that particular direction, then we can approximate
values of the function (for small s) using the formula
Our thoughts lead to very useful ideas that deserve to be codified.
Definition.
Let f be a function defined on some neighborhood of a pointLet ∈ℝn.
be a vector from
ℝn. We say that the function f is differentiable at point
converges.
Then we define the (directional) derivative of f at point
It is actually the derivative of the corresponding function φ,
![]()
which we can evaluate in the usual way. Even easier way will come soon.
Now we can express one of the results in the above example as
We did the definition for general directions
![]() ,
because in some
applications (like physics) it makes sense, but here we will use only
norm-one vectors.
,
because in some
applications (like physics) it makes sense, but here we will use only
norm-one vectors.
In the first chapter we saw that cuts parallel with coordinate axes are more
handy, because then we do not need to introduce a new parameter, we work
with functions
![]() 1 = (1,0,...,0,0),
1 = (1,0,...,0,0),![]() 2 = (0,1,...,0,0)
2 = (0,1,...,0,0)![]() n = (0,0,...,0,1),
n = (0,0,...,0,1),
So what do we get when we differentiate in the direction
![]() 1,
1,
Example.
We return to the function
First we try it by definition. We move along the parametric line
![]() = (0,1),
= (0,1),![]() f (1,2) = φ′(0) = 4.
f (1,2) = φ′(0) = 4.
Alternative approach: We take the function
In such an easy way we can obtain derivative in arbitrary general point
![]() = (x0, y0),
= (x0, y0),
In real life calculations we do not write those subscript zeros, we simply
say that the derivative of
Because these derivatives are so easy to derive and the axial directions are the most important, it is no surprise that this whole idea has a special name.
Definition.
Let f be a function defined on some neighborhood of a pointConsider unit vectors in axial directions, i
..., For
i = 1,...,n we define the partial derivative of f with respect toxi as
if this exists.
In calculations we differentiate with respect to the given variable simply by imagining that the other variables (and expressions that they create) are constant and we differentiate by the given variable using the usual rules.
Example.
Consider the function
We find the partial derivative with respect to x by imagining that
y and z are some particular numbers. Since this is the first time, we actually
show what happens when we really use some numbers for y and z, for
instance 13 and π.
Then
![]()
The same reasoning, but with "y" and "z" as constants, leads us to the result
![]()
Similarly, to get partial derivative with respect to y we imagine that instead of x and z there are constants, say 23 and π, and we run in our minds through the following calculation:
![]()
On paper we then write
![]()
Of course, an experienced derivator (as in "terminator") does not
actually imagine numbers, he/she just learns to pretend that there are
constants at the right places and analyzes the resulting expression. We still
owe you the derivative by z, for that we take x and y
to be constants, then also the whole term
![]()
By the way, the curved sign ∂ that surprisingly does not have a short name (well, you can call it "partial derivative mark") can be used just like the usual derivative mark to indicate derivative of a particular expression, but here we write it from the left. For instance, in the last calculation above we can indicate aplication of the chain rule as follows:
![]()
We already know that partial derivatives tell us how the function changes (grows, falls) in key directions.

In this picture, both partial derivatives are negative, so the graph of this
function goes down as we move from
![]() in directions of coordinate axes.
It might seem that in other directions, a function is free to do whatever it
wants, and that is true in general. However, if we demand that the graph of
the function does not "break sharply", then it looses this freedom.
It may surprise that relatively mild assumptions on the function already
guarantee that its growth and fall in other directions is completely
determined by its behaviour in axial directions.
in directions of coordinate axes.
It might seem that in other directions, a function is free to do whatever it
wants, and that is true in general. However, if we demand that the graph of
the function does not "break sharply", then it looses this freedom.
It may surprise that relatively mild assumptions on the function already
guarantee that its growth and fall in other directions is completely
determined by its behaviour in axial directions.
Theorem.
Let f be a function defined on some neighborhood of a pointIf there exists some neighborhood of exist for all
i = 1,...,n and they are continuous at
The requirement on continuity of derivatives is often satisfied, essentially every function given by an algebraic formula with elementary functions (apart from absolute value) fits in, and for such functions we can deduce derivative in arbitrary direction purely from knowing partial derivatives. This means that the condition of continuous derivatives has a rather large impact.
For convenient manipulation we usually gather all partial derivatives into one packet.
Definition.
Let f be function defined on some neighborhood of a pointIf all partial derivatives for i = 1,...,n exist, then we define the gradient of f at
It is worth noting that gradient is a vector from
For a function with continuous derivatives (in other words, for most functions we normally meet) we can now express the conclusion of the above theorem in an elegant way using dot product,
D![]() f (
f (![]() )
=
∇ f
(
)
=
∇ f
(![]() )•
)•![]() .
.
Example.
Consider
At the point
![]() = (1,2)
= (1,2)![]() f (1,2) =
∇ f (1,2)•(h,k)=2h + 4k,
f (1,2) =
∇ f (1,2)•(h,k)=2h + 4k,
Gradient carries lots of interesting information, it is one of key notions.
Imagine that we are at a point ![]() ,
sitting on the graph and looking
around. Depending on which direction we look at, the graph rises or falls.
The rate at which it changes is given by the directional derivative. In
other words, it is given by the expression
,
sitting on the graph and looking
around. Depending on which direction we look at, the graph rises or falls.
The rate at which it changes is given by the directional derivative. In
other words, it is given by the expression
![]() )•
)•![]() ,
,![]() are unit vectors.
According to a well-known formula,
are unit vectors.
According to a well-known formula,
![]() )•
)•![]() = ||∇ f (
= ||∇ f (![]() )||⋅||
)||⋅||![]() ||cos(α) = ||∇ f (
||cos(α) = ||∇ f (![]() )||cos(α),
)||cos(α),
here α is the angle
between the vectors
![]() )
)![]() .
.
We see that we will climb fastest if we start off so that
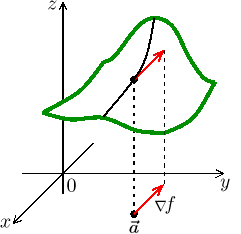
Fact.
Let f be a function that has continuous first partial derivatives on some neighborhood of a point∇ f ( is the direction of the steepest growth of the function f at||∇ f ( there.The vector
-∇ f ( is the direction of the steepest descent at
We are still at a point ![]() and sitting on the graph. A certain level
surely passes through this point of the graph, namely the level
and sitting on the graph. A certain level
surely passes through this point of the graph, namely the level
![]() ),
),![]() lies on the corresponding level set (which is
situated in the domain). If we start off from the point
lies on the corresponding level set (which is
situated in the domain). If we start off from the point
![]() in exactly the
same direction that the level set goes, denote it
in exactly the
same direction that the level set goes, denote it
![]() , then we surely
expect that for at least a little while the value of f does not change
(an infinitely small little while if you like differentials).
This means that
, then we surely
expect that for at least a little while the value of f does not change
(an infinitely small little while if you like differentials).
This means that
![]() f (
f (![]() ) = 0,
) = 0,![]() )||cos(α) = 0,
)||cos(α) = 0,![]() .
.

In other words, the direction at which the appropriate level set starts off from
the point ![]() is perpendicular to the direction of fastest ascent given by
the gradient. Try to imagine this practically. We are standing on a
mountain side, thinking which way to go. Is it really necessarily true that
the direction of sharpest climb is perpendicular to the direction of level
walk? I can easily imagine mountains shaped in such a way that this would
not be true. However, the trick here is that such mountains, considered as
graphs of functions of two variables, would not have continuous
derivatives there.
is perpendicular to the direction of fastest ascent given by
the gradient. Try to imagine this practically. We are standing on a
mountain side, thinking which way to go. Is it really necessarily true that
the direction of sharpest climb is perpendicular to the direction of level
walk? I can easily imagine mountains shaped in such a way that this would
not be true. However, the trick here is that such mountains, considered as
graphs of functions of two variables, would not have continuous
derivatives there.
Fact.
If a function f has continuous first partial derivatives on some neighborhood of a point∇ f ( is perpendicular to the level set passing through
This is very useful. Many objects can be represented as level sets for suitable functions, then the gradient allows one to easily obtain normal vectors to such an object.
Example.
Consider the ellipse given by the equation
![]()
we want to find its tangent line at the point
One possible approach is through graphs. The given point lies on the upper half of the ellipse, where it can be viewed (after solving the formula for y) as the graph of the function
![]()
To find the
tangent line at
![]()
slope of the tangent line is therefore
Alternative approach: We rewrite the given equation into a more pleasant
form
This vector is perpendicular to level sets, therefore also to the ellipse,
therefore also to its tangent line. The equation of the line perpendicular
to
We already mentioned that with functions of more variables it makes no sense
talking about tangent lines. However, when we imagine the graph of some
function of two variables, it seems that there could be tangent planes. For
functions of three variables there should be tangent three-dimensional
spaces (they look "flat" when placed in the four-dimensional space where
the graph lives) and so on. In general, a flat n-dimensional object in
How do we find them? By leaving the world of geometry for the moment and turning to analytical approach. We know that with functions of one variable, the tangent line at a is the line that better than any other line approximates behaviour of f around a,
f (a + h) ∼ f (a) + f ′ (a)h.
How could we best approximate values of a function
![]() = (a1,a2)?
= (a1,a2)?![]() = (h,k).
= (h,k).
Instead of one "diagonal" movement we can arrive at the place
![]()
From the point
![]()
We put it together:
![]()

In the picture (we see the graph from below) we marked values used in approximation using filled circles, whereas correct values are marked with empty circles. We have also shown the tangent lines that we used.
If the function f is sufficiently nice, then the derivative
![]() does not change much when we move by a
really tiny bit, so we can ignore the shift by h in the argument and write
does not change much when we move by a
really tiny bit, so we can ignore the shift by h in the argument and write
![]()
In other words,
![]()
The expression on the right defines a plane and it is exactly the one we were looking for. Its equation is
![]()
or
![]()
It is a plane determined by the normal vector
![]()
Similar reasoning works in more dimensions, we have the estimate
![]()
and tangent hyperplane
![]()
Also here we get the standard form of equation by multiplying out.
Fact.
Let a function f have continuous first derivatives on some neighborhood of a point∇ f ( by one coordinate, namely we add −1 as the(n + 1)th coordinate, we obtain a vector fromℝn + 1 that is perpendicular to the tangent hyperplane to the graph of f at the point
Example.
Consider
We have already found
![]() = (2,4,−1).
= (2,4,−1).
Through which point should the plane go? Since
0 = ![]() •((x, y,z) − (1,2,5))
= 2(x − 1) + 4(y − 2) − (z − 5)
=> 2x + 4y − z = 5.
•((x, y,z) − (1,2,5))
= 2(x − 1) + 4(y − 2) − (z − 5)
=> 2x + 4y − z = 5.
Alternative: Plane perpendicular to the vector
Another alternative: The graph is given by the equation
and we are done.
Conclusion: The tangent plane to the graph of f at the point given by
![]() = (1,2)
= (1,2)
We use this example to review other uses of gradient.
The function f grows fastest when we leave the point
![]()
The point
0 = ∇ f (1,2)•((x, y) − (1,2)) = 2(x − 1) + 4(y − 2) => 2x + 4y = 10.
Using the normal direction
Just like with functions of one variable, also functions of more variables
can be differentiated more times (if they allow us). For instance, with the
function
However, unlike the case of one variable, here we have a choice regarding
what to differentiate and with respect to which variable. A function of two
variables has first order derivatives
![]() and
and ![]() and they both can be
in turn differentiated by x or by y, obtaing four distinct partial
derivatives of order two, for instance the following two. We will show first
a detailed record of the procedure and then the standard condensed notation:
and they both can be
in turn differentiated by x or by y, obtaing four distinct partial
derivatives of order two, for instance the following two. We will show first
a detailed record of the procedure and then the standard condensed notation:
![]()
Note the order of differentiation: The symbols in the denominator are read
from right to left, so we start with derivative by the variable most to the
right. For instance, in the partial derivative of third order
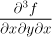 we would first
differentiate f with respect to x, then the result is differentiated by
y and this by x again, whereas to obtain
we would first
differentiate f with respect to x, then the result is differentiated by
y and this by x again, whereas to obtain
![]() we would first differentiate
with respect to y and then twice by x.
we would first differentiate
with respect to y and then twice by x.
Definition.
Consider a function f defined on some neighborhood of a pointLet i1,i2,...,im∈{1,2...,n} be some indices of variables. We define the corresponding partial derivative of order m of the function f by induction as follows:
assuming that all derivatives that are needed exist.
If all the coordinate indicesik are not the same, then we call this derivative a mixed derivative.
Just like derivatives of order one, the higher ones can also be collected into packets.
Definition.
Assume that a function f has all derivatives of order two at a point
Practically speaking, we differentiate the function f by its first variable,
this derivative is then repeatedly differentiated once more, by all
available variables, and the results create the first row of the matrix,
similarly we create the other rows. Note that on the diagonal we have
derivatives of the type
![]() ,
away from the diagonal
there are the mixed derivatives.
,
away from the diagonal
there are the mixed derivatives.
To collect derivatives of the third order we would need a three-dimensional matrix, which brings us to tensors, a topic that we definitely do not want to explore here. In many (most?) applications we can do with the first two derivatives, we settle for them here as well.
There are actually quite a few partial derivatives, for instance, if we work
with a function of three variables, then we are looking at
Theorem.
If a function f has all partial derivatives of order m on some neighborhood of a point
This for instance means that if the function f is at least a bit reasonable (for instance given by a formula put together from elementary functions), then the Hess matrix is symmetric. This allows for some saving on work. When finding second order derivatives of a function of two variables, it is enough to find three instead of four, this is actually not so great and we often calculate all four anyway, since the match of the two mixed derivatives serves as a validity check.
We get better savings when it comes to derivatives of higher order. For a function of two variables it suffices to find four third-order derivatives instead of eight, for a function of three variables it means 10 derivatives of third order instead of 27 and 15 instead of 81 for order four. Actually, this is more of a theoretical saving, since we rarely go higher than second order in applications, but it is a nice thing to have anyway.
We know that for a function of one variable, the second derivative determines its concavity: The sign indicates concavity up or down, the magnitude of the derivative tells us how sharp the bend is. This is where most courses stop. Just to satisfy our curiousity we mention that the third derivative determines the development of concavity as we scan the graph from the left to the right. Positive third derivative means that looking from left to right we see the curve's bend "tightening up", as if we were approaching the centre of a snail's spiral, whereas a negative third derivative signifies relaxation of the bend. We will not even attempt to give geometric interpretation of higher orders.
As usual, things get more complicated once we pass to more variables, so we just look at derivatives of the second order. This is already a bonus as this topic is traditionally ignored in common calculus courses.
The derivatives that are not mixed are the easy part. If we slice a
function's graph in the direction of the x-axis, then
![]() determines concavity of the cut, just
like we are used to, similar information comes from
determines concavity of the cut, just
like we are used to, similar information comes from
![]() ,
,
![]() , etc.
, etc.

On the picture we see an interesting situation, in one direction the
function is concave up and in the other it is concave down. This sends mixed
signals about behaviour of the function there and brings us to the question:
Is it true that just like with growth, the curving of the graph in other
directions is already determined by its concavity in axial directions? Is it
for instance true that if we investigate some function
![]() and obtain positive
and obtain positive
![]() and
and
![]() , then the graph should already be
"concave up in all direction", that is, we expect a dimple at that place?
, then the graph should already be
"concave up in all direction", that is, we expect a dimple at that place?
Surprisingly, the answer is negative, there can be many things going on, even in cases when the function has continuous derivatives of all orders. This shows that it is not a question of quality of the function, but rather a consequence of the fact that the non-mixed second order partial derivatives do not carry enough information. In other words, once we start investigating the curving of the graph, it is not enough to just look at what happens along the axes. We need extra information, and this is when the mixed derivatives come into play.
We first look at the derivative
![]()
and assume that it is positive. The second derivative we apply is by y, that is, we move in the direction of the y-axis. While moving this way, we have
![]()
which means that the function
![]() grows,
that is, the slopes of tangent lines in direction x
are increasing, meaning that these tangent lines are getting steeper.
grows,
that is, the slopes of tangent lines in direction x
are increasing, meaning that these tangent lines are getting steeper.
Can you imagine a situation when you move in the y-direction and tangent lines taken in direction x are turning towards faster growth? Such a graph must be twisted, and that is the meaning of the second mixed derivative, it is the direction and measure of the graph's twist. We will show it on a picture where we look at behaviour at the origin.

To simplify the situation we chose a function that is constant along the axes, which (among other things) means that
![]()
We therefore see directly the influence of the mixed second derivative. To see the shape best, we turned the graph so that the x-axis goes to the right, as we are used to when drawing tangent lines. But then the y-axis must necessarily go away from us.
If the function is sufficiently smooth, then we should have
![]()
so we should get the same picture also when interpreting the expression
![]()
When we move in the x-direction, the slopes of tangents taken in the y-direction are increasing, lines are twisting up. The picture fits well, larger slopes of "y-tangents" means steeper growth in the direction of the y-axis, that is, away from us.
Deformation of a graph of this sort is the reason why concavity information in axial directions does not determine the whole shape. When investigating a graph, we have to compare (in a mathematical way) the convexity influence of non-mixed derivatives and the twisting action as indicated by the mixed derivative. Thus all the information in the Hess matrix comes into play, all entries (all derivatives of the second order) play a role of equal importance. Obviously, this topic shows up in the section on local extrema.
Functions of more variables: Local extrema
Back to Extra - Functions of more variables

