Zde uvedeme pojem posloupnosti. Začneme intuitivním přístupem a explicitní definicí, pak ukážeme rekurzivní definici a definujeme podposloupnost.
Co je to posloupnost? Je možno odpovědět dvojím způsobem, přesně a pochopitelně. Začneme s přesnou definicí, ale pokud vás nezajímá, přeskočte k příkladu za ní.
Definice.
Posloupností rozumíme libovolné zobrazení z množiny přirozených čísel do množiny reálných čísel.
Vlastně bychom měli psát "reálné posloupnosti" či "posloupnosti reálných čísel", protože jsou i jiné. Ty se ale v základním kursu kalkulu neprobírají, takže se obvykle říká prostě jen "posloupnosti".
Protože takováto zobrazení pouze přijímají přirozená čísla jako argument, je
zvykem značit posloupnosti trochu jinak než obvykle zobrazení píšeme. Je
možné vypsat hodnoty T pro n rovno 1,2,3,..., to jest můžeme
psát ![]() nebo
nebo
Příklad: Vzorce ![]() ,
,
Všechny tři definice v našem příkladě mají jedno společné: poskytují vzorec,
který nám umožňuje spočítat přímo libovolný člen dané posloupnosti. Například
její desátý člen je
Ono další vyjádření posloupnosti, výpis (či seznam), je zrádné, protože nespecifikuje, jak vypadají další členy. Samozřejmě že odhadneme, že další člen po 11 má být 13, ale nemůžeme si být jisti. Toto značení se proto používá jen jako pomocné, když chceme získat představu, jak dotyčná posloupnost vypadá. Hodně z vlastností posloupnosti je také možné odhadnout tím, že si nakreslíme její graf. V našem případě vypadá takto:
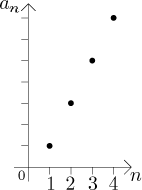
Stejně jako výpis, ani graf není spolehlivý, protože si nikdy nemůžeme být jistí, co posloupnost udělá, poté co uteče z obrázku. Výpis i graf by totiž měly pokračovat do nekonečna, aby ukázaly všechny členy posloupnosti, ale to je evidentně nemožné. Obvykle vypíšeme či nakreslíme dostatečný počet členů posloupnosti, aby se vyznačily její obecné tendence (pokud nějaké jsou), rozumí se, že posloupnost dále pokračuje (jak se n probírá do nekonečna přirozenými čísly) naznačeným způsobem.
Je ještě jiný způsob, jak si zviditelnit posloupnosti. Teď to asi nebude nějak výhodnější, ale bude se to hodit později, až začneme zkoumat funkce. Tento způsob je popsán v této poznámce.
Mimochodem, kdybychom chtěli definovat posloupnost z našeho příkladu podle
definice, použili bychom zobrazení
Teď už jsme připraveni na intuitivní definici posloupnosti:
Posloupností rozumíme nekonečnou, ale spočetnou množinu reálných čísel, u kterých je rovněž určeno pořadí, v jakém jdou za sebou.
V našem příkladě je daná posloupnost prostě jen množina všech lichých přirozených čísel, která jsou seřazena podle velikosti od nejmenšího. To podstatné na posloupnosti jsou právě ony hodnoty a jejich pořadí. Ačkoliv už jsme se zmínili, že výpis (a graf) nejsou spolehlivé při zkoumání posloupností, je fakt, že výpis vlastně přesně vystihuje, co je to posloupnost. Vzorce jsou nutné pro přesné výpočty, ale ty jsou jen pokusem zapsat matematicky podstatu dané posloupnosti a ani nejsou jednoznačné.
Náš příklad a vzorec
Posloupnost daná vzorcem
Je samozřejmě možné modifikovat formální definici posloupnosti, aby také umožnila tyto jiné formy indexování, ale zkomplikovala by se tím, takže většině učebnic to nestojí za to. V praxi ji stejně nepoužíváme.
Poučením je, že tatáž posloupnost může mít mnoho rozdílných
popisů, občas je dokonce dost těžké už jen rozpoznat, že dva popisy dávají
tutéž posloupnost. Člověk by se tedy neměl příliš upínat na jeden konkrétní
vzorec, spíše se snažit soustředit na to, co znamená. Výpis (a graf) často
dají jakési ponětí o základních vlastnostech dané posloupnosti, což je pak v
případě potřeby možné potvrdit matematicky pomocí nějakého popisu vzorcem. To
platí zejména o očíslování. Zatímco indexování
Často je nám dokonce jedno, kterým číslem začínáme indexovat. V takovém
případě prostě zcela vynecháme odkaz na číslování, protože se předpokládá, že
vždycky k indexaci používáme celých čísel, počínaje nějakým určitý číslem.
Pak často píšeme jen
Teď si ukážeme příklad, kdy máme velmi dobrý důvod, proč indexovat
![]() .
.
Je zřejmé, že číslo
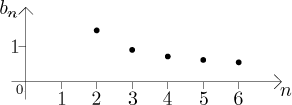
Poznamenejme, že kdybychom opravdu chtěli, tak dokážeme tuto posloupnost
indexovat
V předcházejících příkladech jsme viděli nejběžnější metodu zadávání poslouností: nějakým matematickým vzorcem, ve kterém se vyskytuje n. Tomuto způsobu se říká explicitní definice. Jsou i jiné způsoby. Nejprve ukážeme "definici" výpisem.
Příklad:
Začali jsme číslování nulou, takže pokud označíme členy posloupnosti jako
d, máme
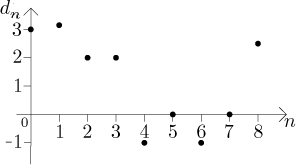
Alternativní graf této posloupnosti je k vidění v této poznámce.
S takovouto definicí se často nestřetáváme; důvodem, je, že to vlastně
definice není. Nepodařilo se nám totiž definovat celou posloupnost. Víme například, že
Jak jsme již předeslali, výpis se používá jen jako nástroj k intuitivnímu
náhledu na obsah posloupnosti. Při neformálním výkladu se občas použije jako
odkaz na jednoduché známé posloupnosti, asi nejčastější je
V následující sekci se podíváme na další způsob zadání poslouposti, tentokráte již správný.
Rekurzivní definice funguje následovně: Specifikujeme vzorec, pomocí kterého lze obdržet určitý člen definované posloupnosti za předpokladu, že známe členy předchozí. Samozřejmě také musíme specifikovat dostatečný počet prvních členů, aby šlo proceduru začít.
Příklad: Posloupnost z našeho prvního příkladu,
(1)
(2)
A opravdu, první člen se shoduje,
Rekurzivní rovnice s n = 2 pak dává
Když se dál pokračuje tímto způsobem, lze se přesvědčit, že první členy těchto dvou posloupností jsou shodné, takže lze také doufat, že posloupnosti jsou stejné. To jde i dokázat matematickou indukcí.
Je možné zkusit i jinou rekurzivní definici téže posloupnosti:
(1)
(2)
První tři členy se zase shodují:
A tak dále.
Hned takto vidíme hlavní rozdíl mezi explicitní a rekurzivní definicí: Rekurzivní definice nám nedovoluje spočítat přímo určitý člen posloupnosti. Přesto je každý člen jednoznačně určen (na rozdíl od "definice" výpisem), takže rekurze je korektním způsobem definice. Mnoho posloupností je možné zadat jak explicitně, tak rekurzivně, ale neexistuje standardní či zjevný způsob, jak přejít z jednoho způsobu na druhý, není dokonce ani standardní způsob kontroly, že dva popisy definují tutéž posloupnost.
Ačkoliv obvykle dáváme přednost explicitní definici (je praktičtější), některé posloupnosti je lepší vyjádřit rekurzivně a některé posloupnosti ani jinak vyjádřit neumíme; někdy tato definice také umožní lépe pochopit, oč v dané posloupnosti jde. Podívejme se na následující posloupnost.
Příklad: Fibonacciho posloupnost je dána vztahy
(1)
(2)
Řečeno slovy, každý člen (kromě prvních dvou) je součtem dvou předchozích
členů. Posloupnost jde
Posloupnost je uspořádaná množina čísel. Když je nějaká dána, její
podposloupnost obdržíme tak, že vybereme nějaké členy z dané
posloupnosti a seřadíme je podle původního pořadí. Například z posloupnosti
A teď formální definice:
Definice.
Nechť{an} je posloupnost. Její podposloupnost obdržíme tím, že vybereme nějaká číslak1 < k2 < k3 <... z indexovací množiny dané posloupnosti a uvažujeme posloupnost.
Příklad: Uvažujme posloupnost
Teď vybereme podposloupnost. Vybereme čísla